
The amount of data is growing exponentially. In fact, global data creation is projected to grow to more than 180 zettabytes by 2025. And, this number is only going to increase with the growth of the Internet of Things (IoT). So, analyzing big data volumes can be daunting; not just because of the quantity of data but also because it is scattered across the enterprise.
Enter Hierarchical Clustering – data analysts’ knight in shining armor. It is the most common method of unsupervised learning to organize big data into meaningful patterns. You can effortlessly analyze these patterns to make data-driven decisions.
In this blog post, we’ll walk you through the fundamentals of hierarchical clustering and its applications in offering personalized search experiences. Let’s get rolling.
What is Hierarchical Clustering?
The process of sorting out data into groups of similar objects (aka clusters) is called hierarchical clustering. Here’s an example to make it simpler for you.
Let’s say you want to cover 15 restaurants in Las Vegas over a period of three days. How will you create an itinerary that covers them all? Most likely you’ll use grouping to create three sets (or clusters) of restaurants that are nearest to each other.
By and large, hierarchical clustering is a process by which data points are classified into a number of groups (or clusters) so that they have maximum similarities within each group and are as much dissimilar as possible from other groups. In the next section, let’s see how it works.
How Hierarchical Clustering Works
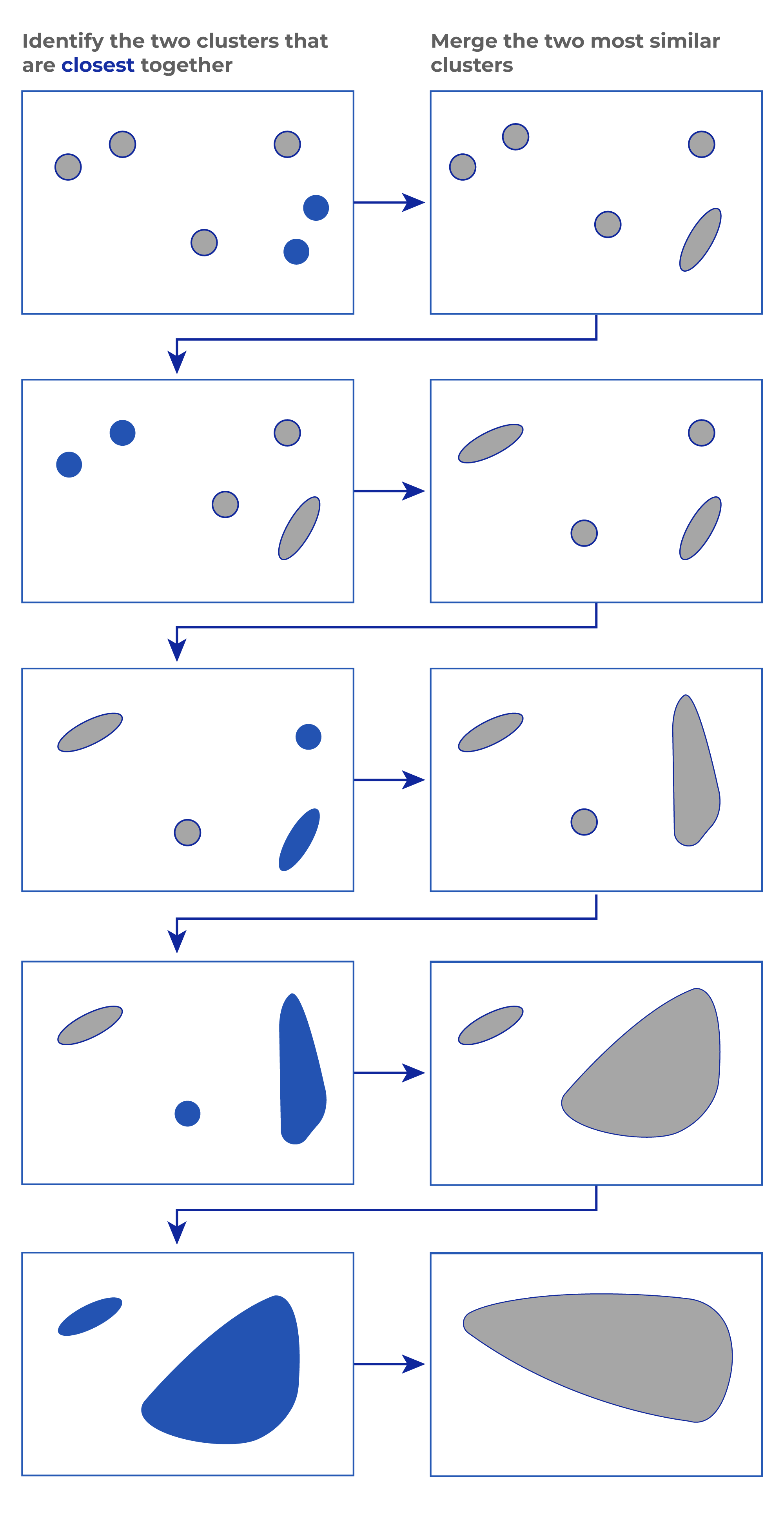
Hierarchical clustering commences by treating each object as a separate cluster. Then, it continually performs the following two steps:
- Identify the closest two clusters;
- Merge the two most similar clusters.
This process continues until the desired number of clusters is reached. Here’s an illustration that explains the working of hierarchical clustering:
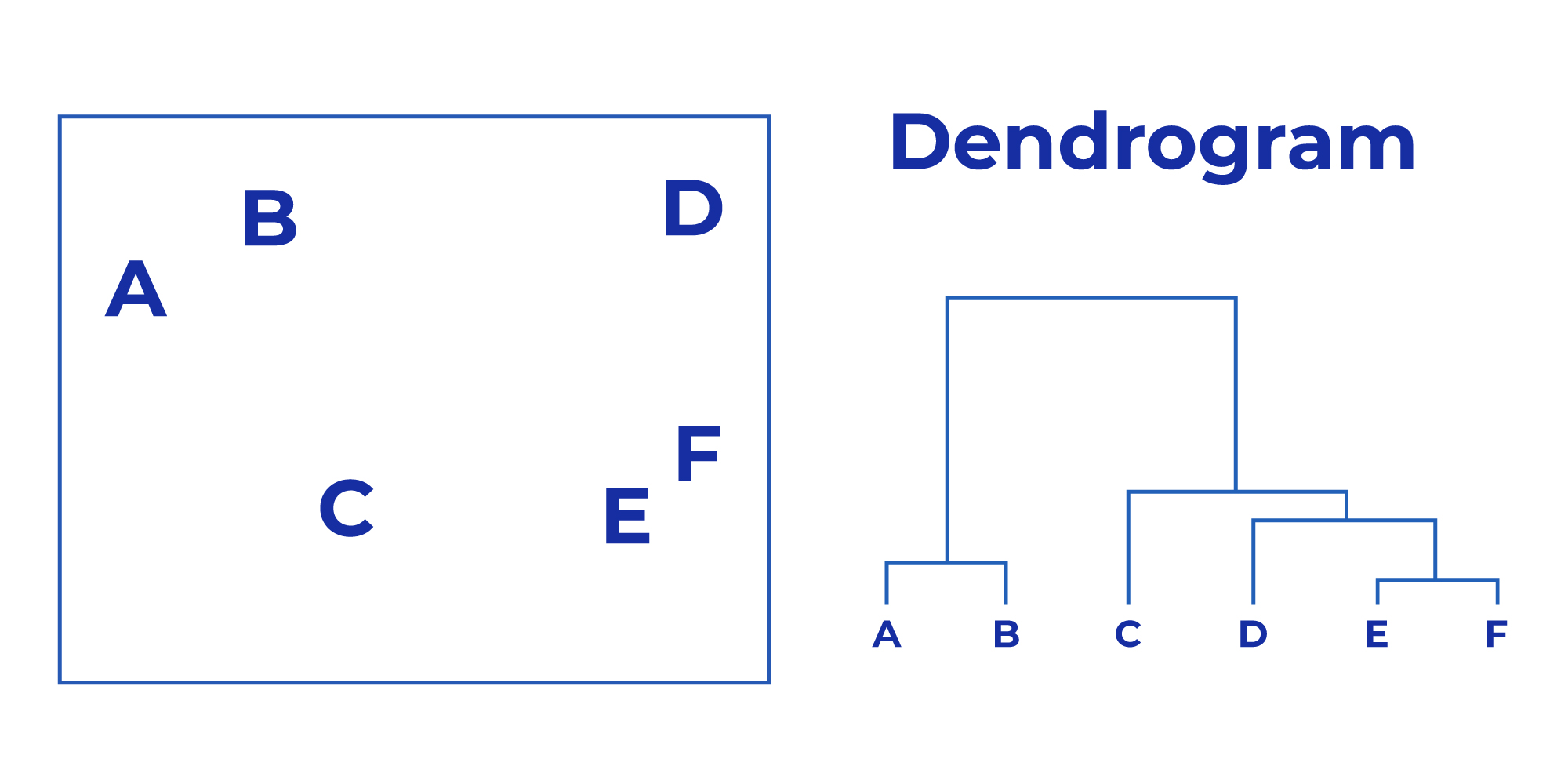
A tree-like diagram called dendrogram represents the hierarchical relationship between the clusters:
Types of Hierarchical Clusters
Typically there are two types of hierarchical clusters, which are as follow:
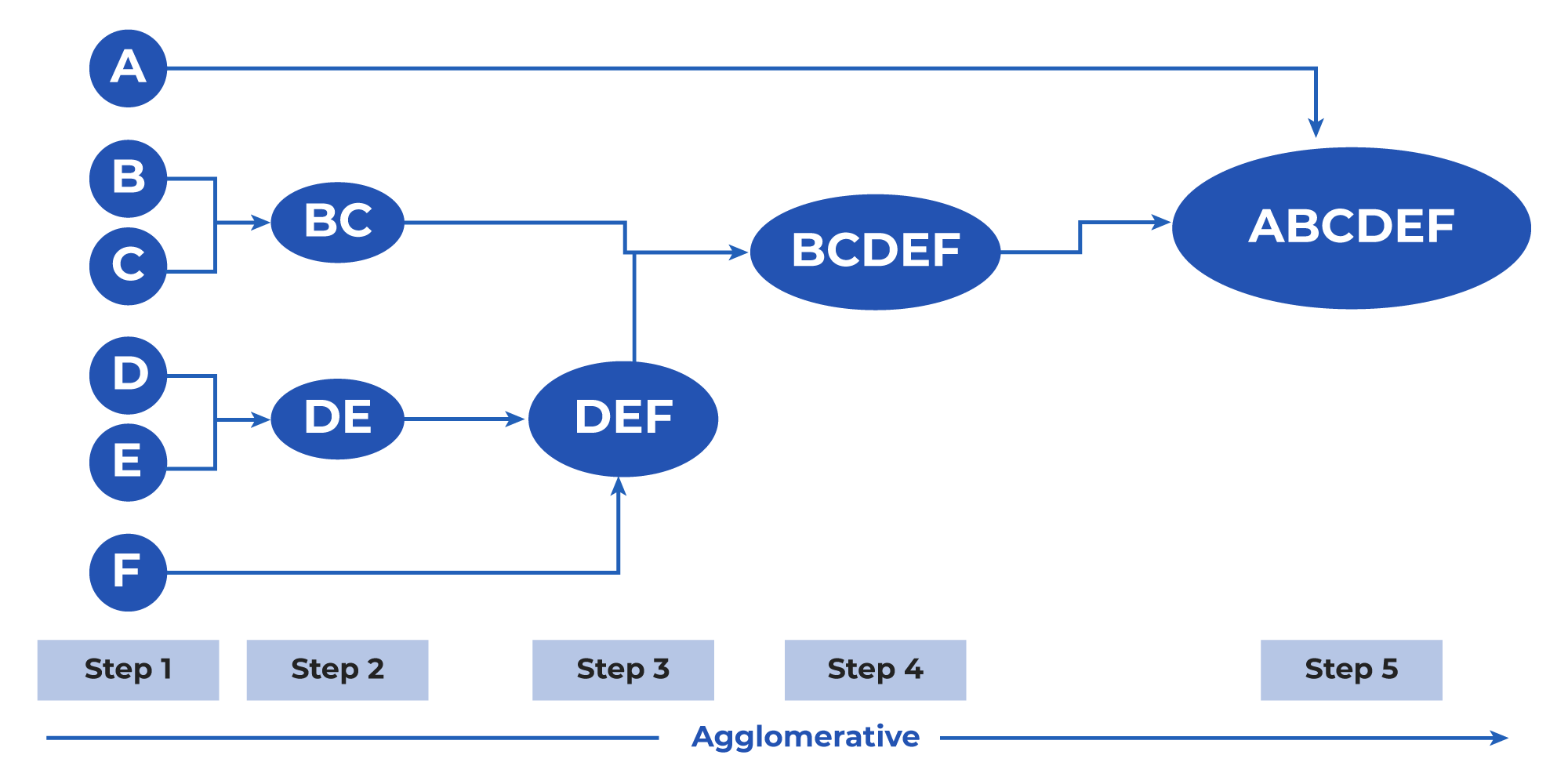
- Agglomerative Clusters: Also known as a bottom-up approach clustering, these clusters consider every data point as an individual initially. Then, at every step, the nearest clusters are identified and merged. The clusters formed in the example above are agglomerative. Another illustration of agglomerative clusters goes as follows:
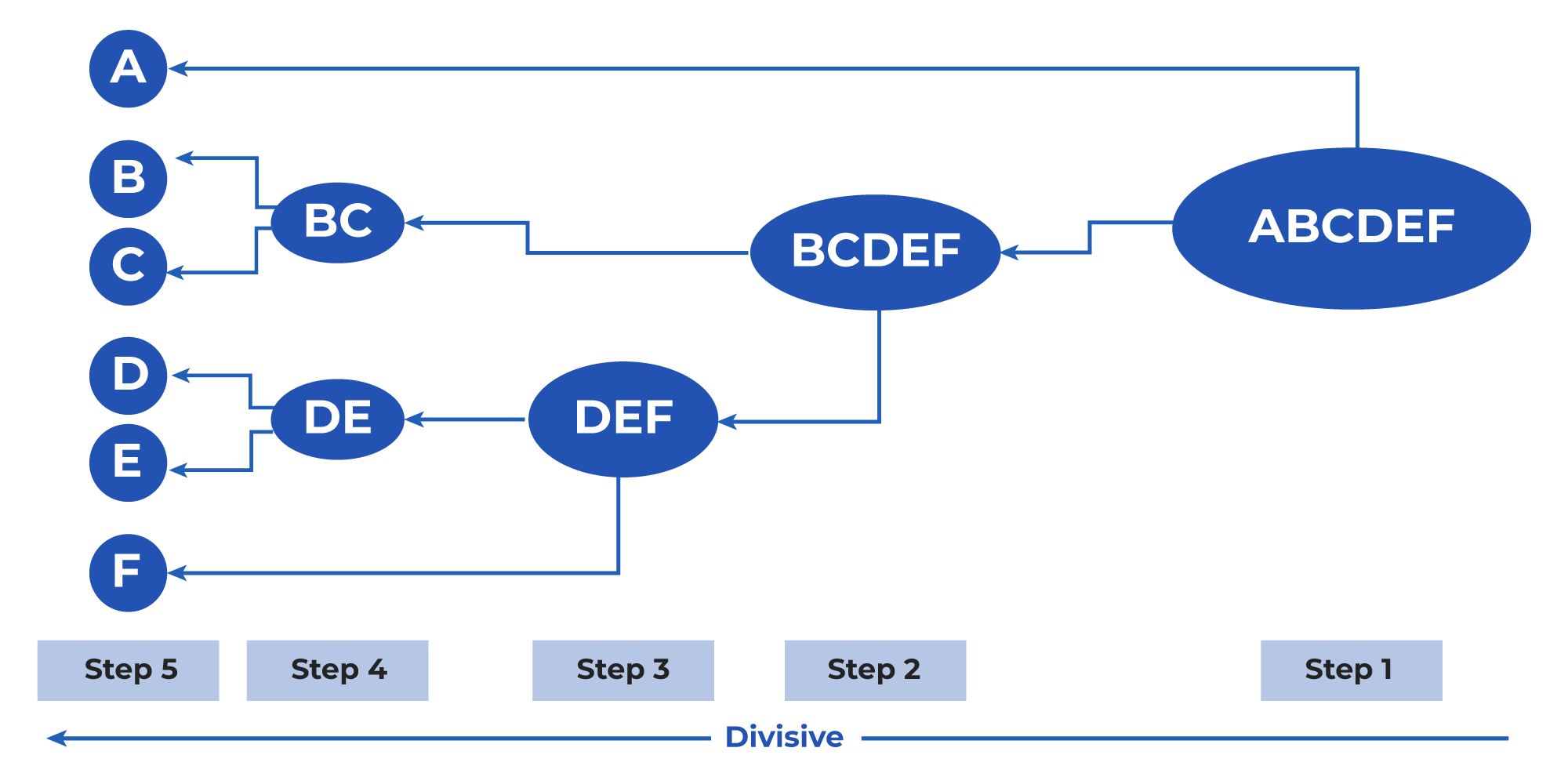
- Divisive Clusters: It is precisely the opposite of agglomerative clusters. It begins by taking into account all the data points as one cluster, and then in every iteration, data points that are dissimilar from the cluster are separated. In the end, N clusters are formed.
Use Cases of Hierarchical Clustering
Let us consider use cases to understand the application of hierarchical clustering better:
Offering Personalized Search Experiences
Hierarchical clustering efficiently clusters the users based on their preferences, behaviors, clicks, and patterns, allowing search engines to tailor the search results according to these groups. Clustering also organizes the content into various topics, leading to more relevant search results.
Additionally, it significantly enhances the search experience by ranking the search results based on the user clusters. It delivers personalized responses, thereby improving the relevance and performance of the search and making users feel more connected to the results.
For instance, enterprise search leverages hierarchical clustering to cluster customers based on their browsing history, purchasing history, and so on, helping to recommend related content.
Identifying Natural Groupings
Another critical use case of hierarchical clustering is its ability to recognize the natural groupings in the dataset. This is not only helpful in data analysis but also intriguing in hypothesis generation.
The benefit of using this for natural groupings is its flexibility to adapt to different data types without prior knowledge of the number of clusters. Also, it provides clustering results in the form of visual representations called dendrograms, which can help interpret and validate the clusters.
For instance: Hierarchical clustering can be used in economic analysis by clustering or grouping various countries on attributes like GDP, inflation rates, unemployment rate, and so on.
Unsupervised Learning
Hierarchical clustering identifies patterns in the data without requiring labeled data. Thus, it is a type of unsupervised machine learning that can be helpful in cases where labeled data is unavailable.
Hierarchical clustering is exceptionally versatile, allowing it to be effectively applied across multiple domains.
For instance, hierarchical clustering can be applied in the healthcare sector to cluster patients based on their medical records. This practical application can assist in identifying risk factors and disease patterns, inspiring real-world solutions.
Want to Know More Ways to Deliver Personalized Experiences?
Personalization is the new norm. And, the organizations that master it are definitely going to pave the way for success. So, it’s high time you debunk the myth of one-experience-fits-all and aim for personalization at scale.
If you are looking for tried-and-tested strategies for personalized support, then here’s an eBook for you. Download it to unveil the secrets of personalization at scale.







