

These quantifiable measures evaluate how effectively and efficiently SUVA resolves customer queries.
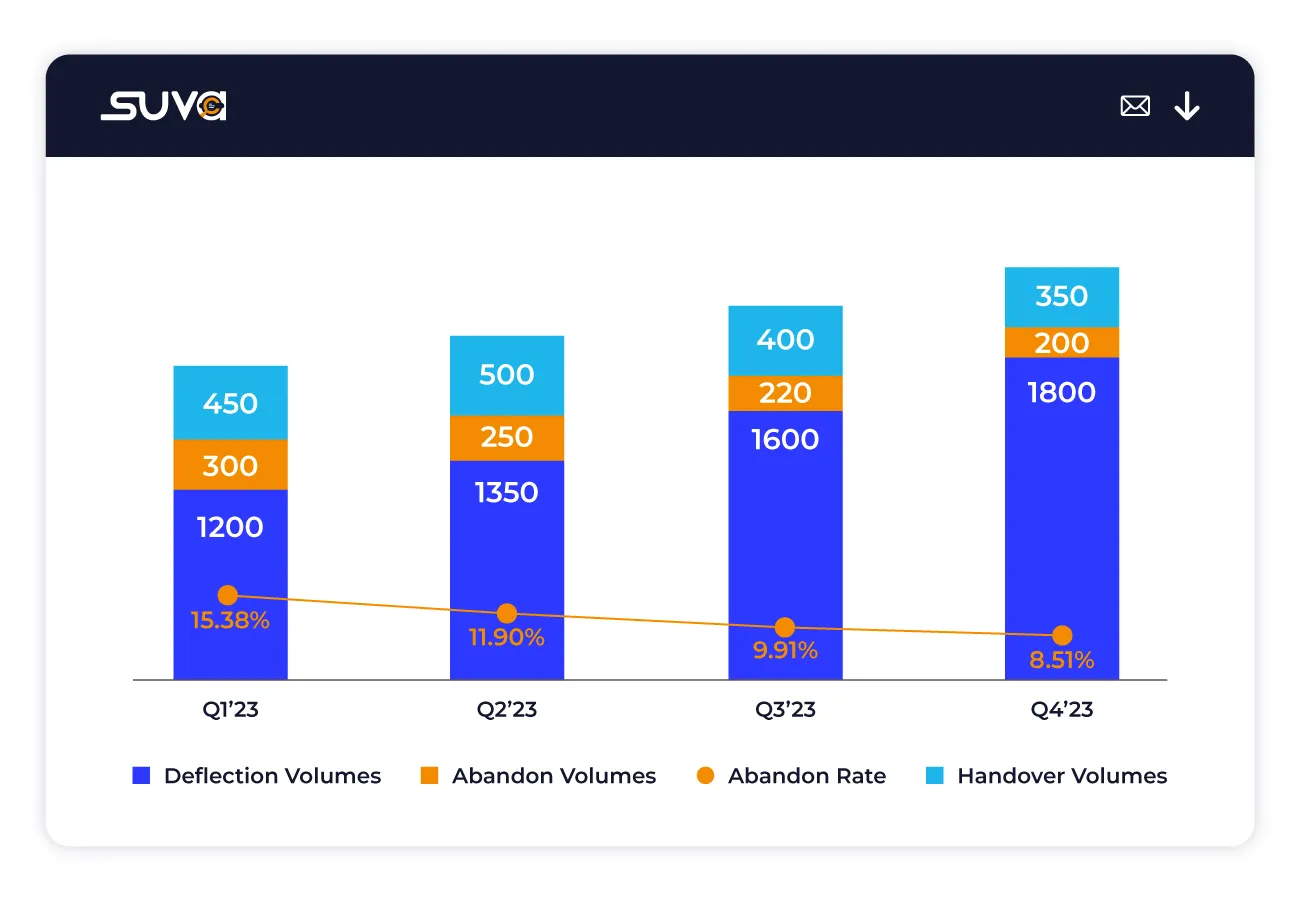
Measure the percentage of queries effectively resolved by SUVA compared to the total chat volume, showcasing SUVA's ability to handle user inquiries independently.
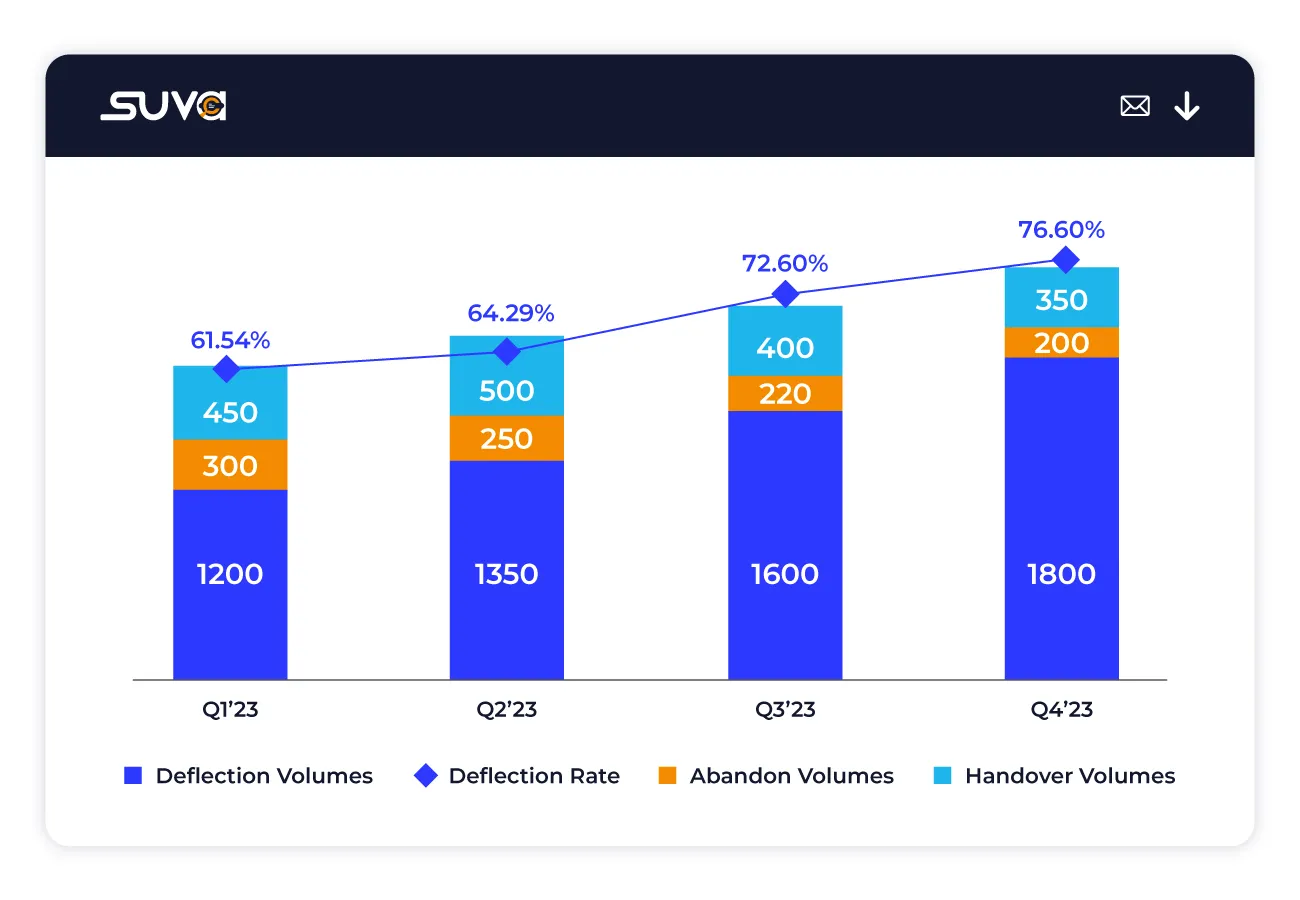
Assess the percentage of queries where SUVA identifies the requirement for human intervention and facilitates a warm transfer to a live agent, ensuring seamless escalation for complex queries.
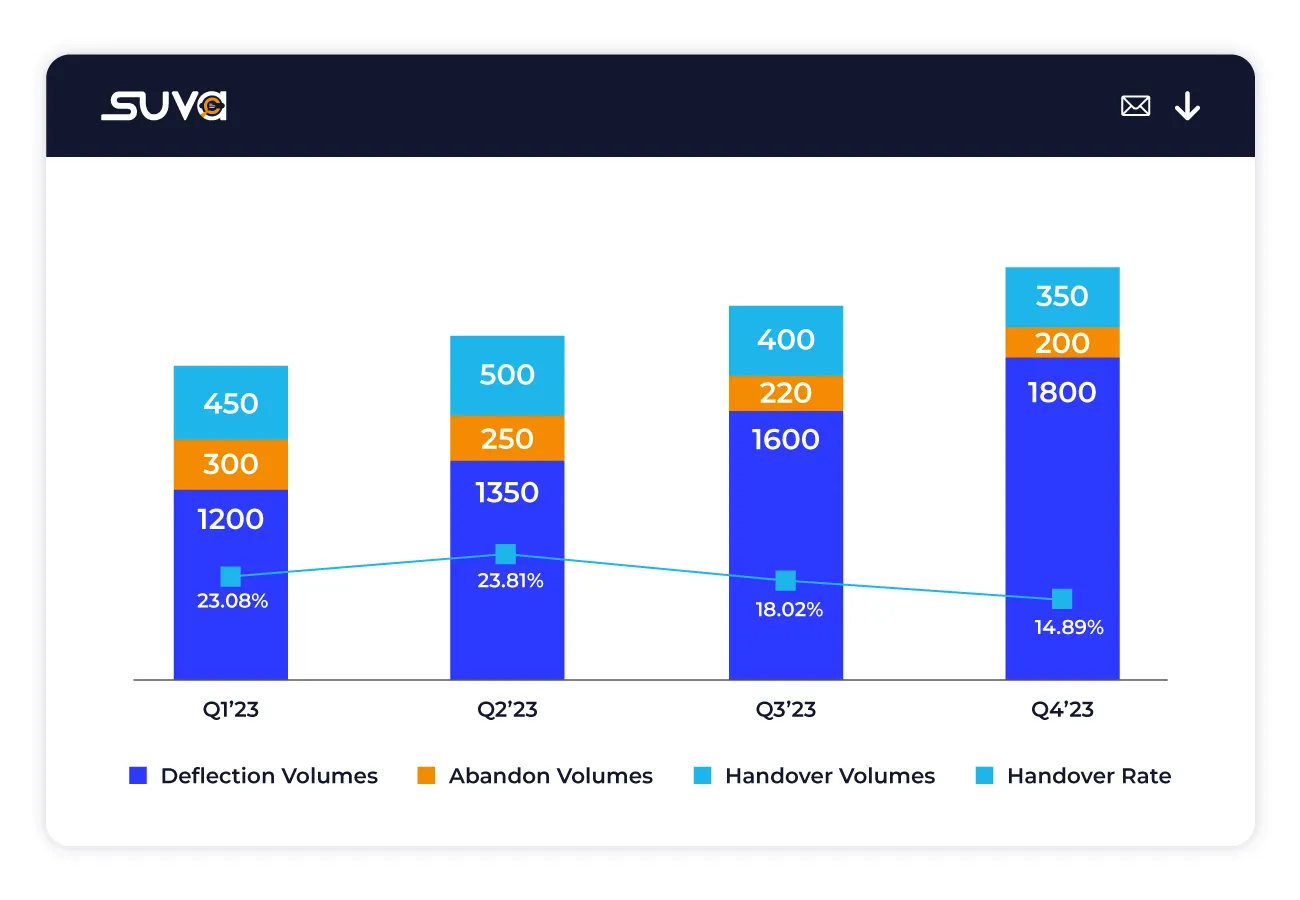
Evaluate the percentage of customer interactions prematurely terminated by users before offering feedback or completing desired actions, providing insights into user engagement and satisfaction levels.
15 Days free trial. No credit card required*
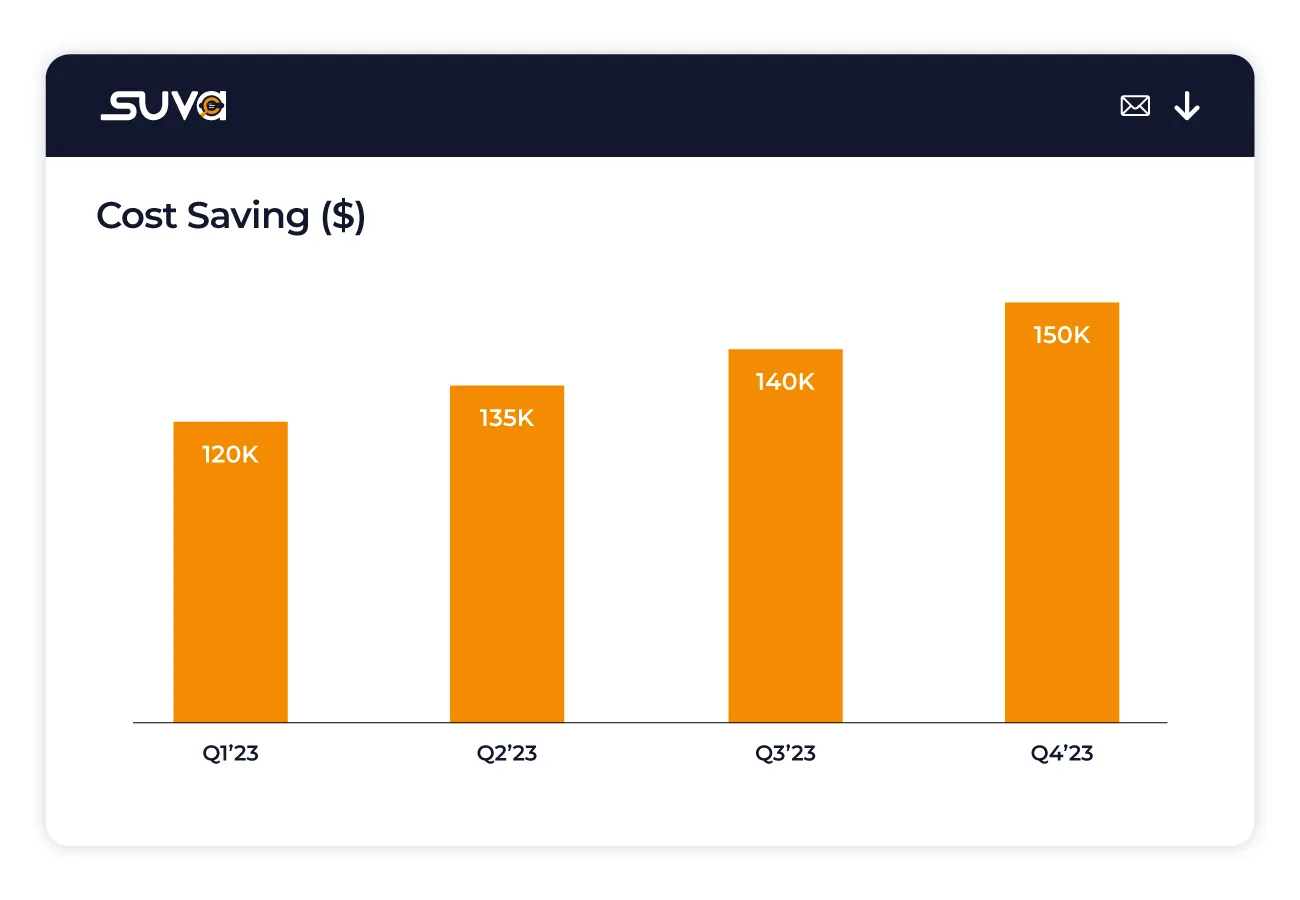
These metrics assess the return on investment (ROI) associated with SUVA implementation.
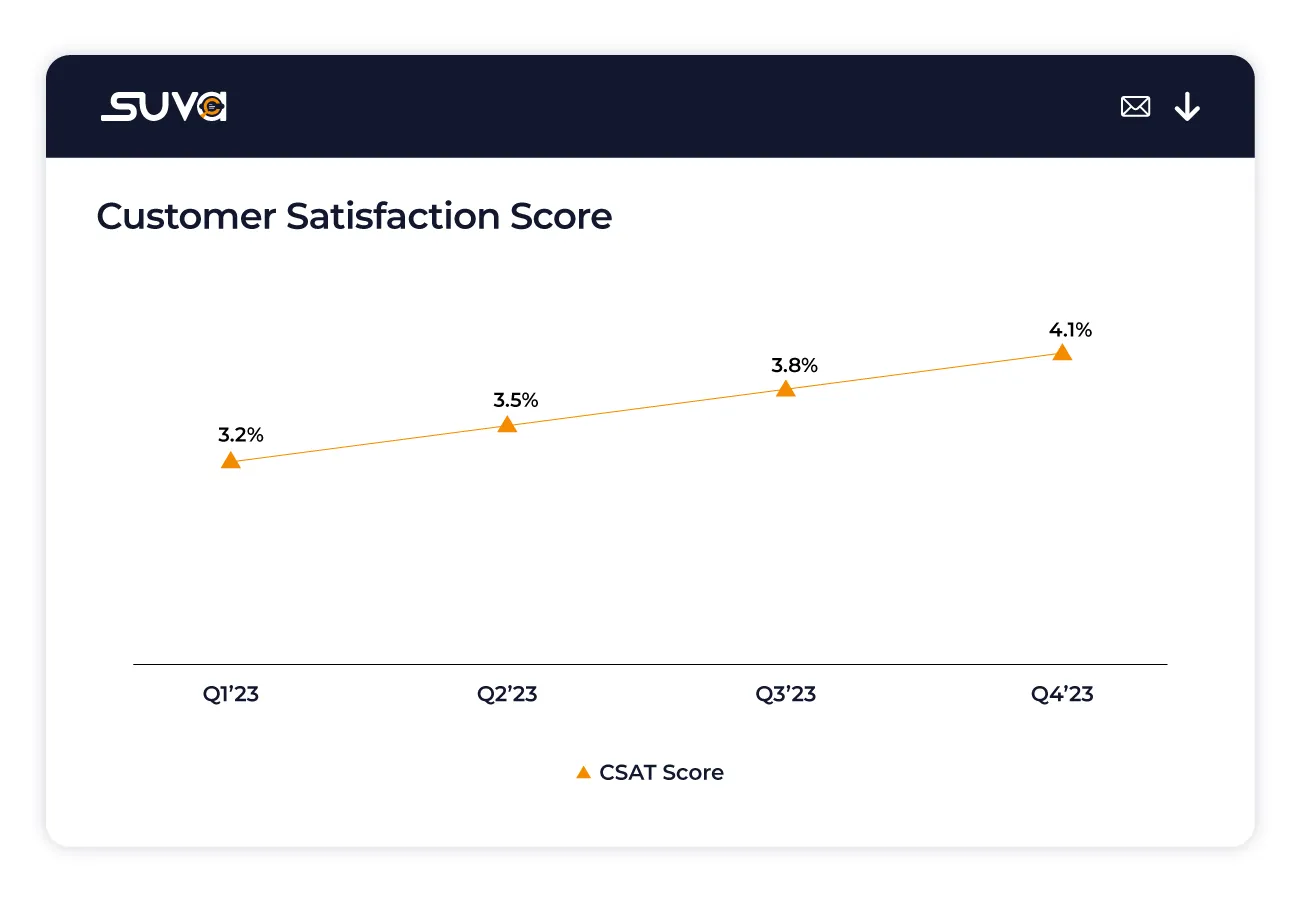
Usually assessed through post-interaction surveys or feedback mechanisms, providing invaluable insights into user satisfaction levels and overall service quality.
This metric is calculated using the formula: Deflection Volume (queries resolved by SUVA) multiplied by the Average Cost per Case, offering a clear understanding of the financial benefits derived from SUVA usage in terms of reduced support costs.
Start Exploring SUVA Analytics to Uncover Actionable Insights and Drive Informed Decisions for Your Business Success!
Get Started NowThese metrics encompass key aspects of user interactions with large language models (LLMs)
Usually assessed through post-interaction surveys or feedback mechanisms, providing invaluable insights into user satisfaction levels and overall service quality.
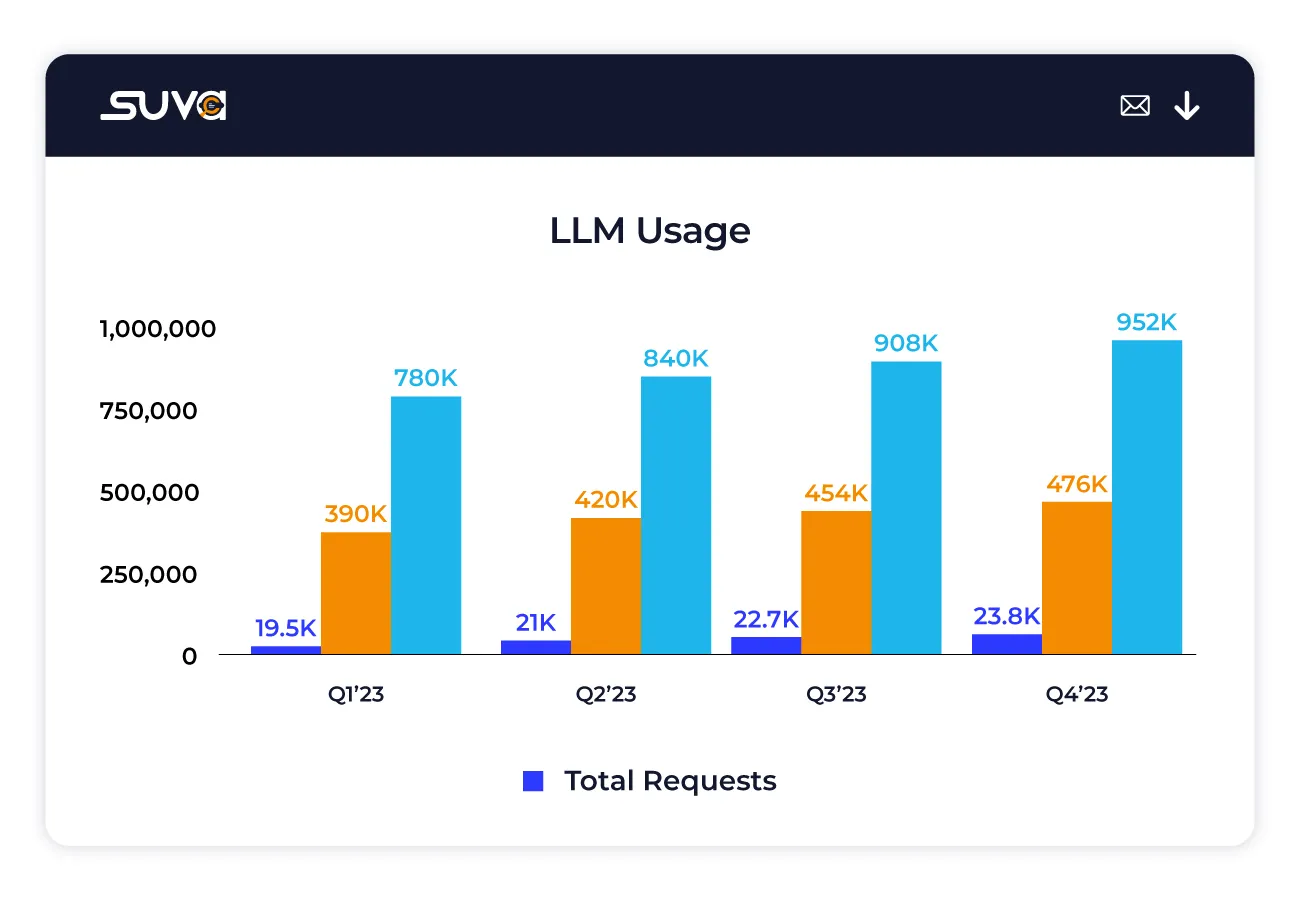
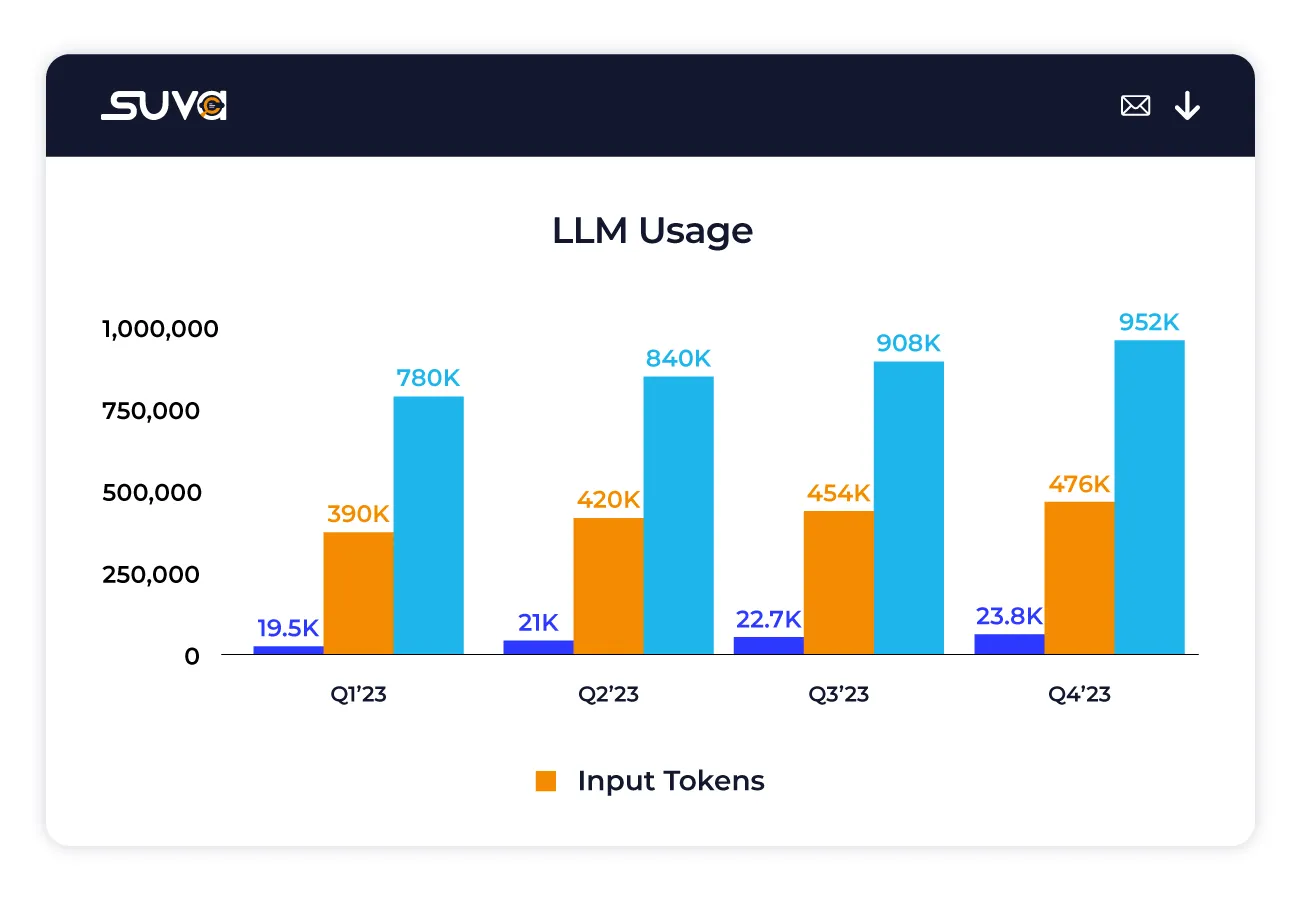
Measure the total number of tokens used by the LLM to process user queries, offering insight into the complexity and depth of interactions with the LLM.
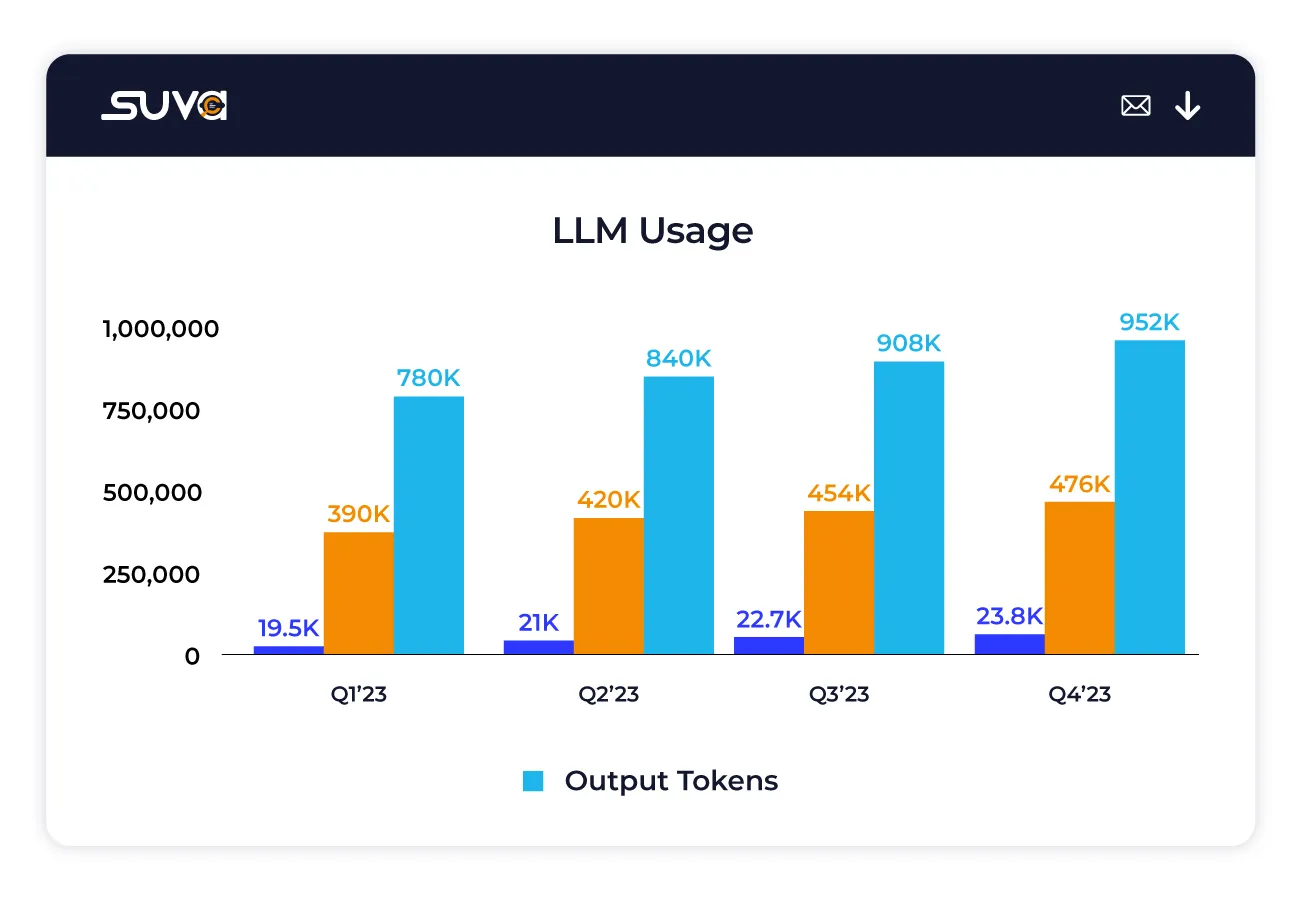
Assess the total number of tokens utilized by the LLM to generate contextual chat responses, reflecting the richness and detail of the generated content.
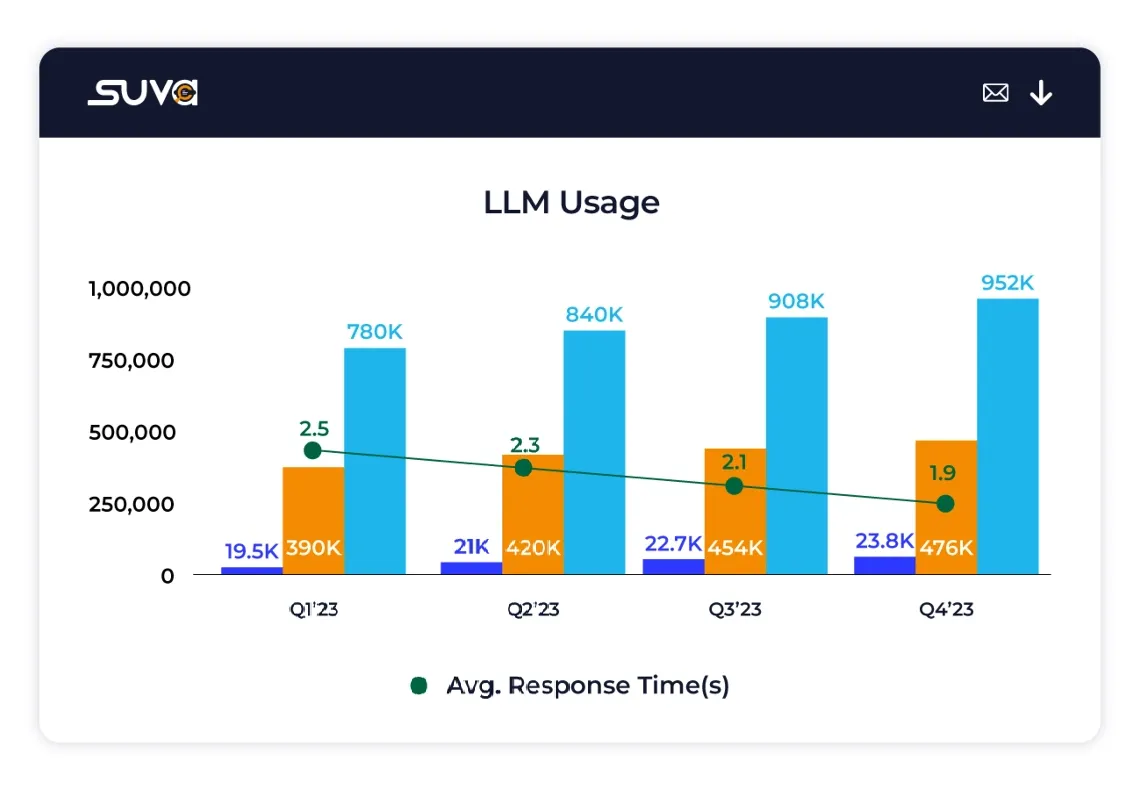
Calculate the average duration taken by the LLM to process and respond to queries, aiding in understanding the efficiency and responsiveness of LLM-driven interactions.
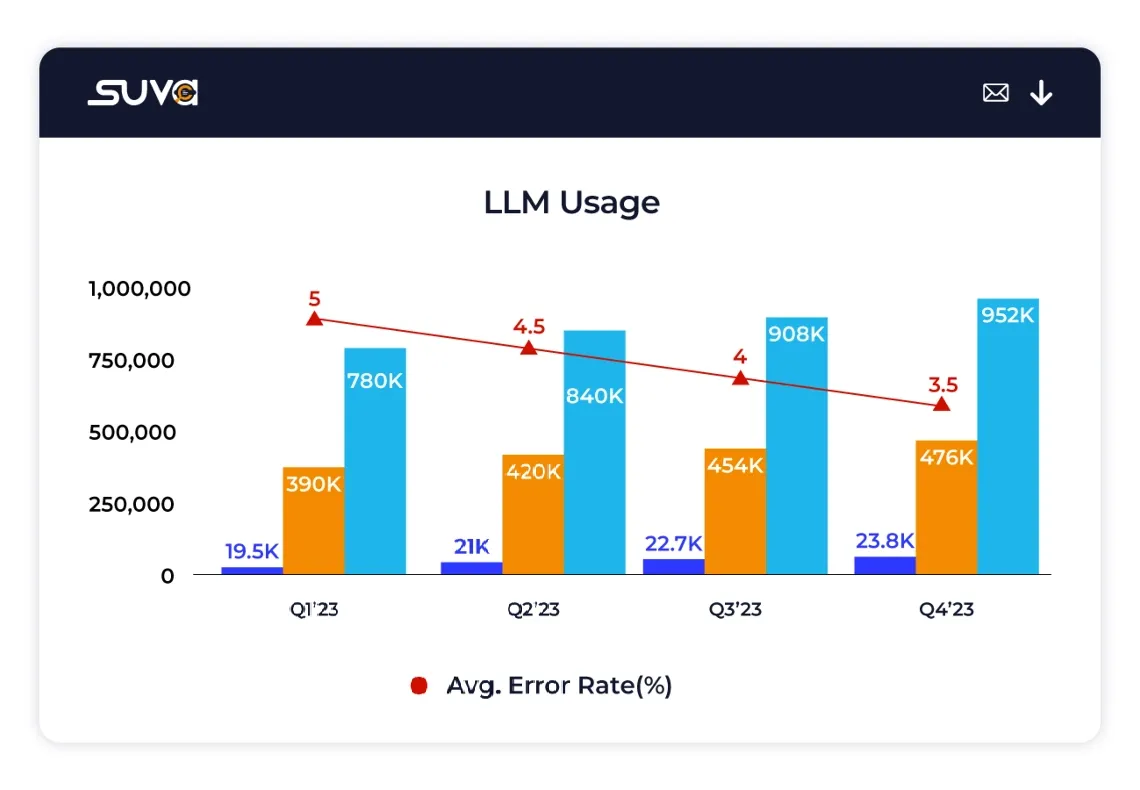
Evaluate the average percentage of queries where the LLM fails to respond, offering insights into areas for improvement and fine-tuning of LLM capabilities.
Ready to Elevate Your Customer & Employee
Experiences? Let's Talk




