
A well-organized knowledge base is an integral part of every successful organization as it offers a place for users to acquire product-related information. This helps reduce the support ticket volume, providing support reps the time to focus on more complex activities.
But studies have shown that support agents can spend up to 20% of their time—which equals one day a week—searching for knowledge. As a result, the crucial tasks paramount to overall customer satisfaction take a backseat, increasing the churn rates.
This is where KCS (Knowledge-Centered-Service) comes into play. Having this framework in place prevents your service desk from all the content findability havoc. It helps capture resolutions at scale and in ways that are both findable and reusable. That means no more tab hopping and switching platforms.
But, have you ever wondered: what is the quality of these knowledge nuggets generated? How comprehensive, precise, consistent, and clear are they?
Taking it to the Next Level: Content Standard Checklist
In comes, Content Standard Checklist previously referred to as Article Quality Index (AQI) –a component that measures the quality of knowledge articles written by various authors.
The idea behind this tool was that there should be a standard unit for measuring article quality spread across channels. This is why calibrating articles to the content standard checklist helps the knowledge workers decipher the broader picture of the piece. It also helps address any technical inaccuracies that are vital for the continued development of a knowledge base, shared with the individual author and the management team.
What are its Essential Elements?
Although, the content standard checklist contains a number of checks and balances (used in the form of yes/no), six of them play a very important role. And these include:
- Uniqueness: Reckons and compares uniqueness of the content piece as compared to the entire KB before giving it final scores.
- Completeness: Evaluates if the article is comprehensive in describing the problem, its cause, and its resolution. It also includes the complete description and types of the topic under discussion.
- Clarity: Determines if the statement is a complete thought or a sentence.
- Accurate Title: Another important determinant of a good article is its title which should cover the main issue and description that a user is looking for.
- Validity of the Links: Relevancy of the hyperlinks is another check that is equally important. It not only helps boost the findability of the related articles but also creates an internal knowledge reserve for the management and employees.
- Metadata: Gauges whether the audience, type, and article state are defined as per the content checklist. This is important for crawlers and boosting search results.
Despite the fact that these checks are helpful, their scope is limited when it comes to human intervention. It is also a tedious job to check the health of so many articles in the knowledge base and cherry-pick the ones that suit our needs.
This is where SearchUnify’s Knowbler, an ML-powered support application, comes to the rescue.
Curious about Knowbler and its real-world uses? Keep reading to know.
Knowbler Role in Automating and Advancing the Algorithm
The core architecture of the Knowbler helps automate knowledge creation, propel knowledge linkage, surfaces intel on KCS health, drives Content Quality & Consumption & so on.
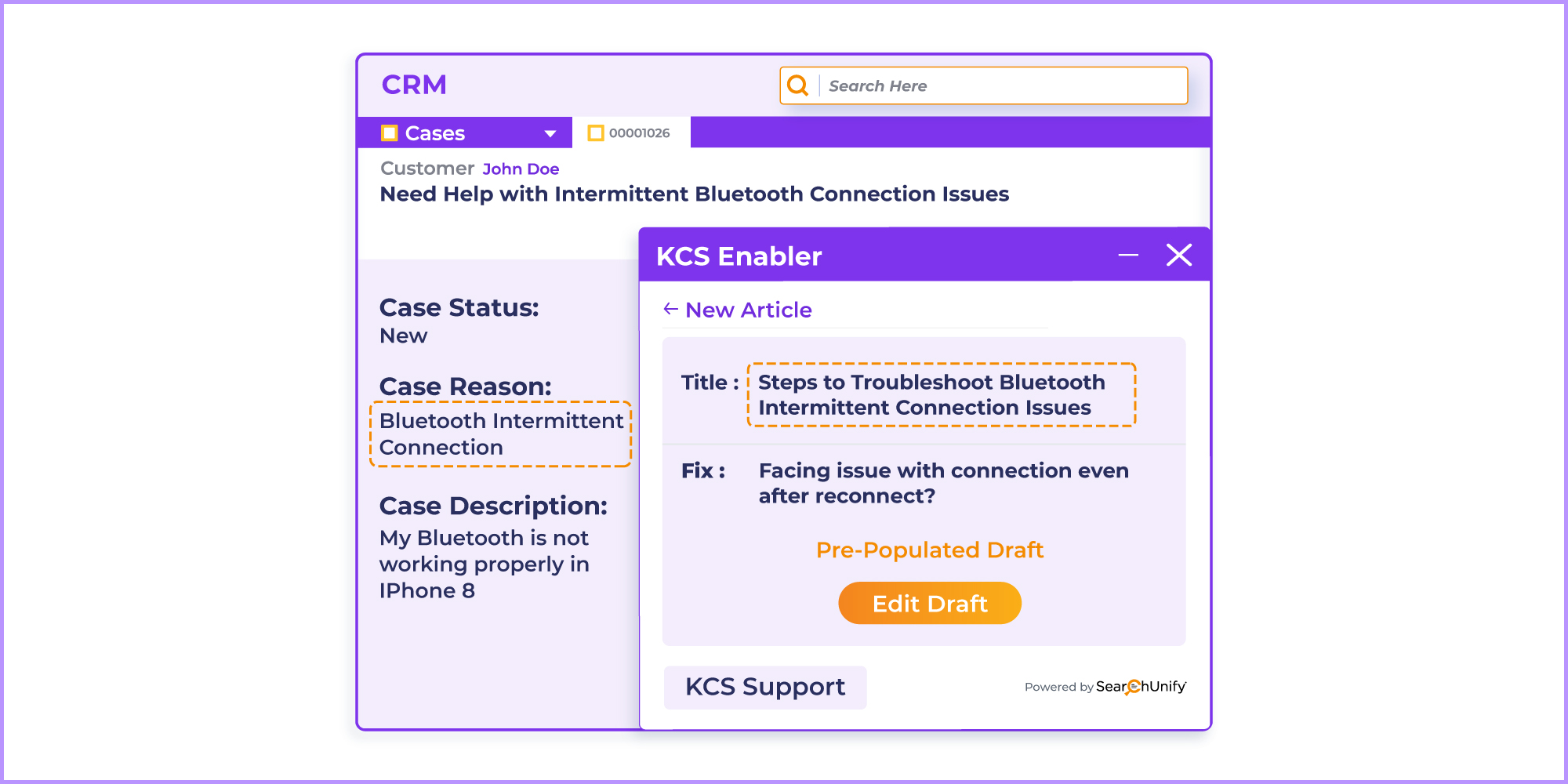
It also helps automate draft composition and exalt content health by using a highly advanced ML quality checker. This checker converts the text into numeric vectors (embeddings) to compare the similarity quotient of the nuances, which helps in producing top-tier knowledge pieces. These similarities include:
- Jaccard Similarity
- Cosine Similarity
- Jaccard and Cosine similarities are combined with any word embedding algorithm (like SBERT), etc.
All of these techniques and algorithms help judge the four essential parameters (as per the content standard checklist), which are:
1. Uniqueness
As part of our machine learning pipeline, Knowbler creates shingles (n-grams) for the article and compares the nuances using the Jaccard similarity model. Once done, the algorithm creates Tokens and generates multiple embeddings using Cosine Similarity. If the number of tokens created in the description are below the threshold then we pass the whole description to generate the embedding. If not, we break the description into smaller sentences and take the average of sentence embeddings.
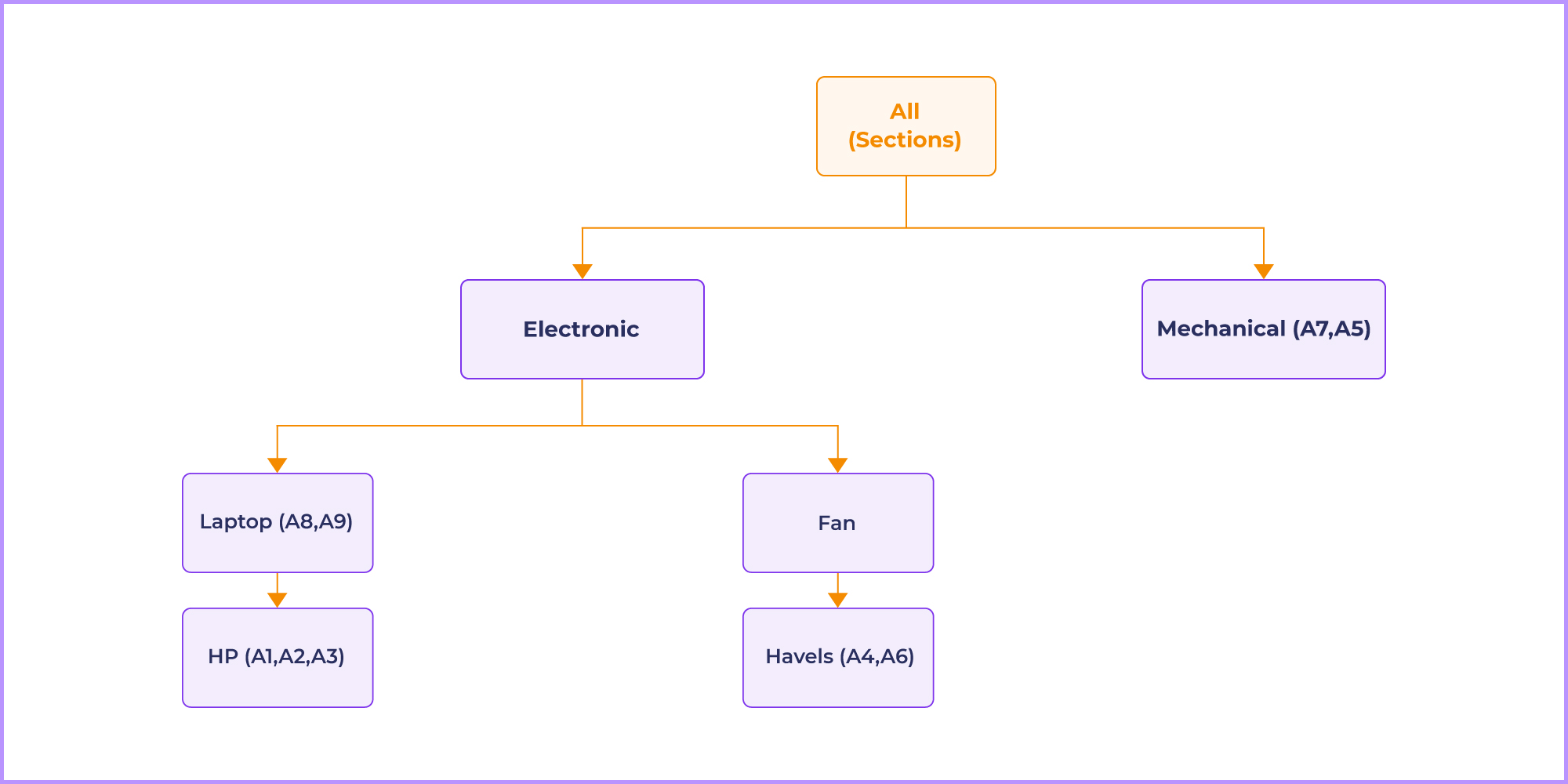
ML algorithm then creates a hierarchical tree structure based on the categories and sections in the article to find the unique score, calculated using the formula:
Unique score = 1- similarity score
For example:
If Electronic and Mechanical are two different sections, then Knowbler will generate two different hierarchies to interpret the score of uniqueness.
2. Title Relevancy
The ML algorithm determines the syntactic (grammatical structure of the text) and semantic (meaning of the text) similarities of the nuances here. This is done by tokenizing and creating embeddings using the SBERT model.
For example:
“McAfee Antivirus in the laptop”
After removing the stopwords, 3 tokens can be obtained from this sentence. Since 2 tokens are already present in the description, the syntactic score is 50%
Similarly, the semantic score is calculated using cosine similarity between the title and description of the article.
And after finding both the syntactic and semantic scores, the final score of the title is calculated using the formula:
Final score=(semantic_score+syntactic_score)/2
3. Link Validity
Here all the hyperlinks from the populated article are extracted and calculated on the basis of two thresholds 200 or 403. Then the final score is calculated using the following parameters:
- If one link is invalid then the score will be pushed to 60.
- If two links are invalid then the score will be punished to 20.
- If more than two links are invalid then the score will be 0.
- If all the links are valid then the score will be 100.
4. Metadata
The ML algorithm determines if the tags and keywords used in the article are present in the description or not.
For example:
Electronic and Laptop are two tags in the article. Then the algorithm will check whether these tags are present in the description or not. And then the final score is calculated using the formula:
{(Number of Values present)/(Total Number Value)}*100
So,
If only the Laptop tag is present then the predicted score will be 50%
If both the Laptop and Electronic tags are present, the final score will be 100 %
If none of the tags are present then the final predicted score will be 0%
Are you ready to deploy Knowbler and make it to the list of top authoring coaches?
If not, we highly recommend you do. Especially as we have overhauled its capabilities in Mamba ‘23–adding a more advanced Administration panel that not only helps manage your subscription, store credentials, add new admins, and review admin logs, but also evaluate the article score manually as predicted by the ML. This state-of-the-art technological upgrade gives a lot of control to the KCS coach than what is anticipated.
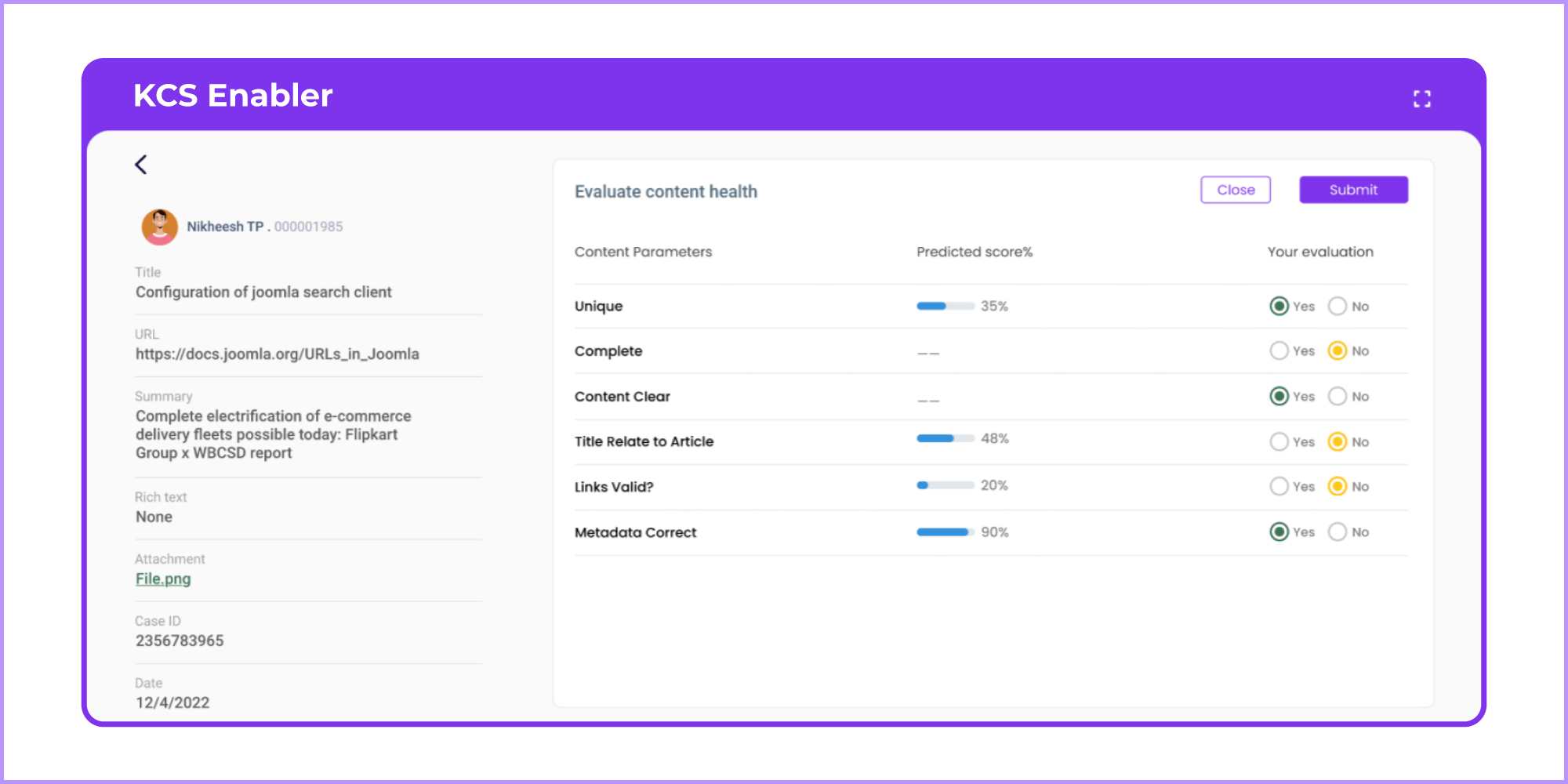
So, don’t forget to gobble the new capabilities of Knowbler added just for YOU!






